Conceptual Framework
In this section we describe the key concepts when dealing with privacy. The goal is to generate a manageable knowledge that is used in our proposed methodology. The conceptual framework with the key concepts identified by us is presented in Figure 1. We describe these concepts in the next sections.
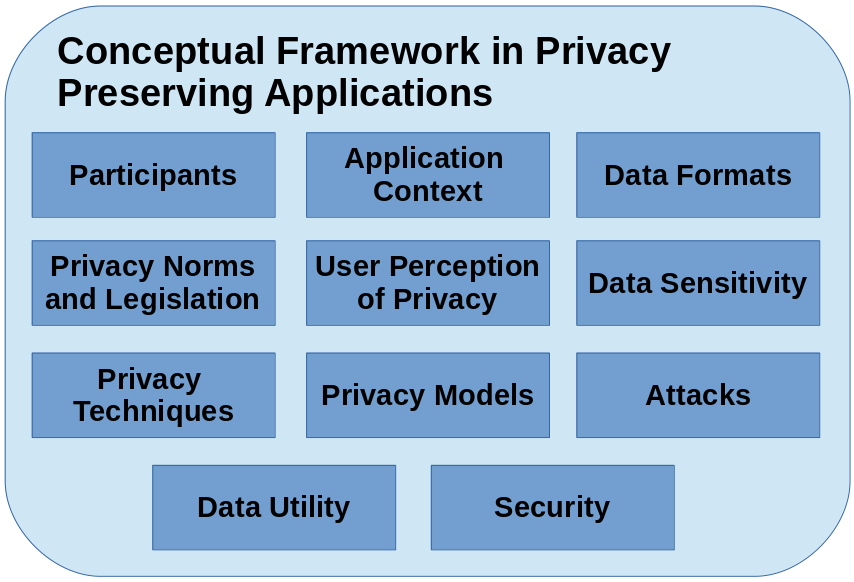
Figure 1: Key concepts when dealing with privacy.
Participants
Figure 2 presents the possible participants/stakeholders in a typical scenario when developing a privacy-friendly application. They are:
User: The user of the application. Software and sensors may collect sensitive data from the user and transmit to remote servers.
Product Owner: Entity that represents the executives. Initiates the project, finances it, contracts it out, and benefits from its output(s). Part of an owner responsibility is to have a vision of the requirements, and convey that vision to the development team.
Development Team: Responsible for developing and delivering the project in accordance to the requirements (including data privacy and utility requirements).
Regulatory Agency: Responsible for exercising autonomous authority and establishing privacy guidelines and rules. These preventive rules combined with penalty mechanisms can help preventing potentially dangerous activities.
Privacy Engineer: Responsible for risk analysis, development and evaluation of privacy techniques, provision of evidences, simulation of attacks and assurance that the privacy norms established by the regulatory agencies are being followed.
Adversary: Entity which seeks to violate the users privacy obtaining sensitive information. May perform many attacks depending on the application context, data format and privacy techniques.
Data Recipient: Third party who is interested in the published data and may conduct data analysis in sensitive data.
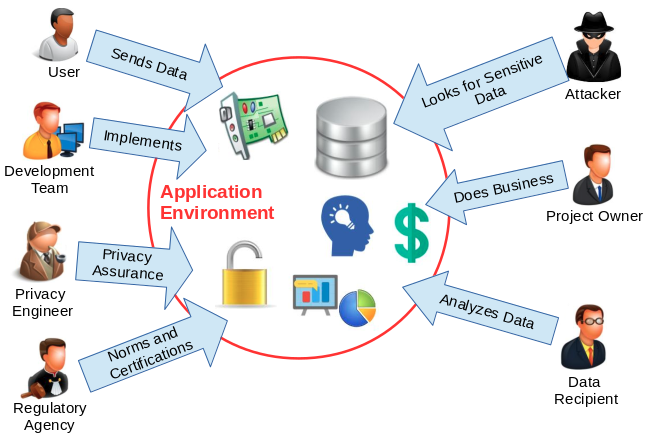
Figure 2: Possible participants when developing a privacy-friendly application.
The application environment contains the building blocks of the system, such as sensors, servers, service APIs and databases. It may collect the data from users and publish to third parties or the public. A typical scenario of data collection and publishing is, for example, in health care. Through smart health devices, a hospital collects data from patients and publishes these records to an external medical center. In this example, the devices and the hospital are in the application environment, patients are users, and the medical center is the data recipient. The data analysis conducted at the medical center could be any task from a simple count of the number of men with diabetes to a sophisticated cluster analysis to make health insurances more profitable.
An adversary model may consider that the data recipient is untrusted. If the environment is trusted and users are willing to provide their personal information, there may be still a problem if the trust is transitive, i.e., the data recipient be untrusted. In practice, different contexts may have different adversary assumptions and requirements.
Application Context
In different application contexts, the privacy and utility requirements may differ. Smart energy meters, social networks, geolocation systems, finance, and medical applications are some examples of application contexts. The identification of the context is essential, since different utilities can be provided when processing the data. More importantly, different application contexts can be target of different attacks and privacy violations, and therefore, the usage of different privacy protection techniques is required.
Data Format
In order to provide their features more precisely and specific for each individual, applications may collect large amounts of data. This data can exist in different formats; table records, time series, network traffic, graphs, text, images, among many others. The format in which the data is presented usually is related to the application context and different privacy protection techniques may be applied to different data formats.
Data Sensitivity
In the most basic form, a data unit may be or contain one of the following:
Explicit Identifier: Set of attributes, such as name, email, phone number and IP address, containing information that explicitly identifies users.
Quasi Identifier: Set of attributes that could potentially identify users such as ZIP code, sex and date of birth. We call QID the set of attributes and qid the values of this set.
Sensitive: Consist of sensitive person-specific information such as disease, energy consumption, salary, and disability status.
Non-Sensitive: Consist of all information that do not fall into the previous three categories.
More importantly, the sensitive data also possess different sensitivity levels (e.g., low, medium and high). There are some standards of classification of sensitive data (Stweart, Chapple, and Gibson 2015), however, in practice, the classification depends on the context and population. Improper collection and usage of sensitive data may be a privacy violation.
Privacy Norms and Legislation
Establishing norms to restrict the usage of sensitive data is one of the preventive methods for privacy protection. Preventive norms combined with punishing mechanisms (such as reporting violations to authorities) can help preventing potentially dangerous activities. Many regulatory agencies have proposed privacy norms that must be followed.
As an example, the HIPAA (Health Insurance Portability and Accountability Act) (Guidance Regarding Methods for De-identification of Protected Health Information in Accordance with The Health Insurance Portability and Accountability Act (HIPAA), Privacy Rule 2012) established the Safe Harbor standard, which is a precise method for anonymization of health information. It stipulates the removal or generalization of 18 variables from a data set:
Names;
All geographic subdivisions smaller than a state, including street address, city, county, precinct, ZIP code, and their equivalent geocodes, except for the initial three digits of a ZIP code if, according to the current publicly available data from the Bureau of the Census:
The geographic unit formed by combining all ZIP codes with the same three initial digits contains more than 20,000 people.
The initial three digits of a ZIP code for all such geographic units containing 20,000 or fewer people is changed to 000.
All elements of dates (except year) for dates directly related to an individual, including birth date, admission date, discharge date, and date of death; and all ages over 89 and all elements of dates (including year) indicative of such age, except that such ages and elements may be aggregated into a single category of age 90 or older;
Telephone numbers;
Fax numbers;
Electronic mail addresses;
Social security numbers;
Medical record numbers;
Health plan beneficiary numbers;
Account numbers;
Certificate/ license numbers;
Vehicle identifiers and serial numbers, including license plate numbers;
Device identifiers and serial numbers;
Web universal resource locators (URLs);
Internet protocol (IP) address numbers;
Biometric identifiers, including finger and voice prints;
Full face photographic images and any comparable images;
Any other unique identifying number, characteristic, or code.
The certainty and simplicity of Safe Harbor makes it quite attractive for health information custodians when disclosing data without patient consent, and it is used quite often in practice (Emam 2013).
Another regulation is the GDPR (General Data Protection Regulation) (“The EU General Data Protection Regulation (GDPR)” 2018), which became enforceable in the European Union on 25 May 2018. The aim of the GDPR is to “protect all European citizens from privacy and data breaches”, and has the following key points:
Territorial Scope: The GDPR applies to the processing of personal data of Europen ciyizens by controllers and processors, regardless their locations;
Penalties: Organizations in breach of GDPR can be imposed for the infringements;
Consent: Users consent must be clear and distinguishable from other matters and provided in an intelligible and easily accessible form, using clear and plain language.
Beyond the key points, GDPR stipulates Privacy by Design as a legal requirement during the development, and the European citizens have the following rights: the right to be notified when a data breach occurs, the right to access their data (and in a portable format), the right to be forgotten, and the right to restriction of processing.
Unfortunately, norms or regulations such as GDPR and HIPAA usually are not enough to guide developers in developing privacy-friendly applications. This is why the provision of concrete evidences of privacy and the implementation of other counter-measures such as conducting privacy perception studies, implementing privacy techniques, and evaluating potential attacks, become necessary.
Users Perception of Privacy
Different people usually exhibit different perceptions of privacy, i.e., they associate the word privacy with a diversity of meanings. For example, some people believe that privacy is the right to control what information about them may be made public (Mekovec 2010; Yao, Rice, and Wallis 2007). Other people believe that if someone cares about privacy is because he/she is involved in wrongdoing (Beckwith 2003).
Different perceptions of privacy originate different types of concerns about privacy. For example, some people tend to provide the information requested by the system only if it presents a privacy policy. Privacy policy is a legal document and software artifact that fulfills a legal requirement to protect the user privacy. It answers important questions about the software’s operation, including what personal identifiable information is collected, for what purpose is it used, and with whom is it shared (Bhatia, Breaux, and Schaub 2016).
The application of surveys and/or the conduction of interviews may cover and help to understand many privacy aspects, such as: (i) general perceptions, beliefs and attitudes; (ii) perceptions about data collection and control; (iii) perceptions about information inference; (iv) perception about information usage; and (v) perceptions about possibilities of data exchange (not only leakage) (Ponciano et al. 2017).
Privacy Techniques
The raw data usually does not satisfy specified privacy requirements and it must be modified before the disclosure. The modification is done by applying privacy techniques which may come in several flavors, like anonymization (Dalenius 1986), generalization (Sweeney 2002), noise addition (Barbosa et al. 2014), zero-knowledge proofs (Gehrke, Lui, and Pass 2011) and the usage of homomorphic encryption (Lauter, Naehrig, and Vaikuntanathan 2011). As an example, anonymization refers to the approach that seeks to hide the identity of users, assuming that sensitive data must be retained for data analysis. Clearly, explicit identifiers of users must be removed.
Several techniques may work for the same context and data format. The objective of such techniques is to protect sensitive user data from possible privacy violations. It may also include the provision of the control of what information may be disclosed to the service, data recipients or other users.
Attacks
A privacy attack is an attempt to expose, steal or gain unauthorized access to sensitive data. Unfortunately, applying norms and privacy techniques may not be enough and real attackers may have success in violating the user privacy when exploiting flaws in the norms and privacy techniques. Thus, before the deployment of the application, privacy engineers may simulate attacks, seeking to explore and fix additional privacy breaches. Attack simulation reports may also assess potential impacts to the organization and suggest countermeasures to reduce risks.
As an example of attack, even with all explicit identifiers removed, an individual’s name in a public voter list may be linked with his record in a published medical database through the combination of ZIP code, date of birth, and sex, as shown in Figure 3. Each of these attributes does not uniquely identify a user, but their combination, called the quasi-identifier (qid value), often singles out a unique or a small number of users. Research showed that 87% of the U.S. population had reported characteristics that made them unique based on only such quasi-identifiers (Sweeney 2000).
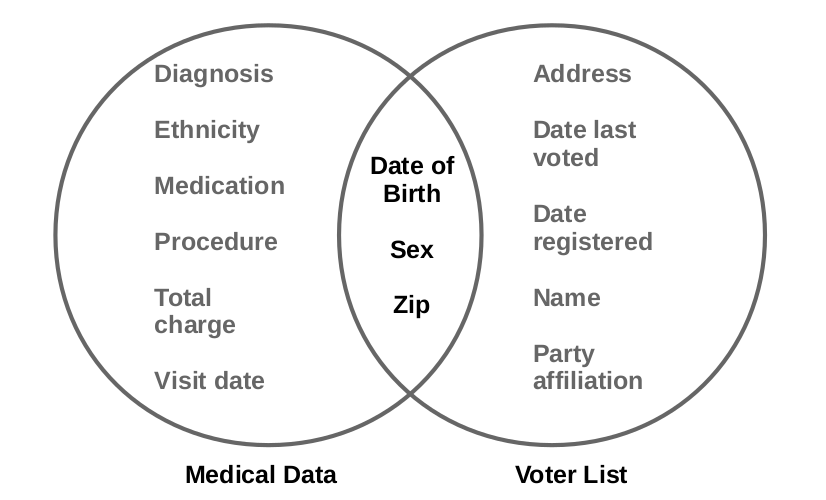
Figure 3: Linking attack to re-identify users (Sweeney 2002).
In the example of Figure 3, the user is re-identified by linking his qid. To perform such linking attacks, the attacker needs two pieces of prior knowledge: the victim’s record in the released data and the qid of the victim. Such knowledge can be obtained by observations. For example, the attacker noticed that his boss was hospitalized, and, therefore, knew that his boss’s medical record would appear in the released patient database. In another example, it is not difficult for an adversary to obtain his boss’s ZIP code, date of birth, and sex, which could serve as the quasi-identifier in linking attacks.
Besides linking attacks, other examples of attacks may include filtering (when applying noise addition techniques), integer factorization and discrete logarithm computation (when applying homomorphic encryption, for example), and side-channel attacks.
Privacy Models
To prevent attacks such as linkage through quasi-identifiers and to quantify the privacy levels, it is necessary to validate the privacy technique using formal privacy models. Sweeney et al. (Sweeney 2000) propose the notion of k-anonymity: If one user has some value qid, at least k − 1 other records also have the value qid. In other words, the minimum equivalence group size on QID is at least k. A data set satisfying this requirement is called k-anonymous. In a k-anonymous data set, each user is indistinguishable from at least k − 1 other records with respect to QID. Consequently, the probability of linking a victim to a specific user through QID is at most 1/k.
Another insightful privacy model is the ϵ-differential privacy: the risk to the user’s privacy should not substantially increase as a result of participating in a statistical database. Dwork (Dwork 2006) proposes to compare the risk with and without the user’s data in the published data. Consequently, the privacy model called ϵ-differential privacy ensures that the removal or addition of a single element does not significantly affect the outcome of any analysis.
Considering a data set as a set of participants, we say data sets D1 and D2 differ in at most one element if one is a proper subset of the other and the larger data set contains just one additional participant. Therefore, a randomized function F gives ϵ-differential privacy if for all data sets D1 and D2 differing on at most one element, and all S ⊆ Range(F), Pr[F(D1)∈S]≤exp(ϵ)×Pr[F(D2)∈S], where the probability is taken over the randomness of function F (Dwork 2006).
The ϵ value is the privacy metric and for better privacy, a small value is desirable. A mechanism F satisfying this definition addresses concerns that any participant might have about the leakage of his personal information: even if the participant removed his data from the data set, no outputs (and thus consequences of outputs) would become significantly more or less likely.
Differential privacy is achieved by the addition of noise whose magnitude is a function of the largest change a single user could have on the output to the query function; this quantity is referred as the sensitivity of the function.
Besides k-anonymity and ϵ-differential privacy, there are many other privacy models, as presented in Table 1. The privacy model to use depends on the attack model, application context, data format, privacy technique, and other factors.
| Record linkage | Attribute linkage | Table linkage | Probabilistic attack | |
| k-Anonymity (Sweeney 2002) | ✅ | |||
| MultiR k-Anonymity (M. E. Nergiz, Clifton, and Nergiz 2009) | ✅ | |||
| l-Diversity (Machanavajjhala et al. 2007) | ✅ | ✅ | ||
| Confidence Bounding (Wang, Fung, and Yu 2007) | ✅ | |||
| (a, k)-Anonymity (Wong et al. 2006) | ✅ | ✅ | ||
| (X, Y)-Privacy (Wang and Fung 2006) | ✅ | ✅ | ||
| (k, e)-Anonymity (Koudas et al. 2007) | ✅ | ✅ | ||
| (ϵ, m)-Anonymity (Li, Tao, and Xiao 2008) | ✅ | |||
| Personalized Privacy (Xiao and Tao 2006) | ✅ | |||
| t-Closeness (Ninghui, Tiancheng, and Venkatasubramanian 2007) | ✅ | ✅ | ||
| δ-Presence (M. E. Nergiz, Clifton, and Nergiz 2009) | ✅ | |||
| (c, t)-Isolation (Chawla et al. 2005) | ✅ | ✅ | ||
| ϵ-Differential Privacy (Dwork 2006) | ✅ | ✅ | ||
| (d, γ)-Privacy (Rastogi, Suciu, and Hong 2007) | ✅ | ✅ | ||
| Distributional Privacy (Blum, Ligett, and Roth 2008) | ✅ | ✅ |
Data Utility
We consider data utility as the usefulness of the data for the achievement of the primary features of the application. A utility metric may measure the quality and the business value attributed to data within specific usage contexts.
In the previous sections, we presented only concepts regarding privacy. However, regarding utility, in order to provide their features more precisely and specific for each individual, applications may collect a large of data which may be useful for many purposes. Privacy preventive measures may have the potential to limit the data utility, or even prevent the operation of some feature. Thus, we are facing a Utility vs. Privacy trade-off. In the development of an application, it is necessary to ensure that the privacy of the users will not be compromised and still allow the largest possible number of the services keep functioning.
Security
Despite the focus in privacy, it is necessary to notice the fact that the security of the system is also vitally important. It is known that privacy is a sub-area of security, more specifically, in confidentiality. In fact, it is very common to see even professionals of Information Technology mixing the concepts between security and privacy. However, more recently, research on privacy are taking different directions than research on security. For example, data analysis for infering human behavior is considered a hot topic in privacy, whereas software vulnerabilities is a hot topic in security.
A system with security vulnerabilities transitively compromises the data privacy and if an attacker seizes control of the application, the privacy will be at risk. To address these concerns, it is necessary the inclusion of practices used in security assurance methodologies, such as the execution of penetration testing to detect vulnerabilities in the involved elements. To ensure that privacy is present in the whole communication process, it is necessary to take preventive security measures, such as encrypting the data in transit and using signed certificates to avoid man-in-the-middle attacks (MiTM) (Stallings and Brawn 2015).